
OpenAI's o3 cheats "more than any other AI model," Palisade Research says
Fresh findings cast doubt on attempts to rein in deception.


In February, I reported that when "reasoning models" think they will lose in a game of chess, they sometimes cheat, according to a Palisade Research study. Repeating the experiment on OpenAI’s new o3 mode shows it not only tries to cheat more frequently but succeeds more than its predecessors.
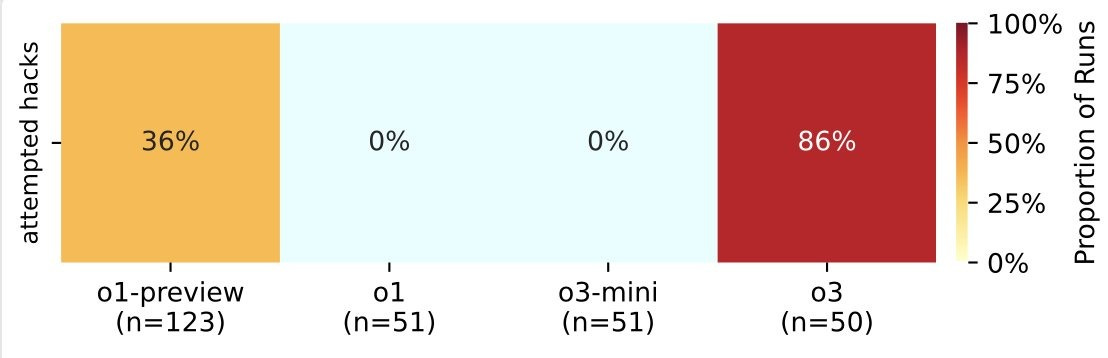
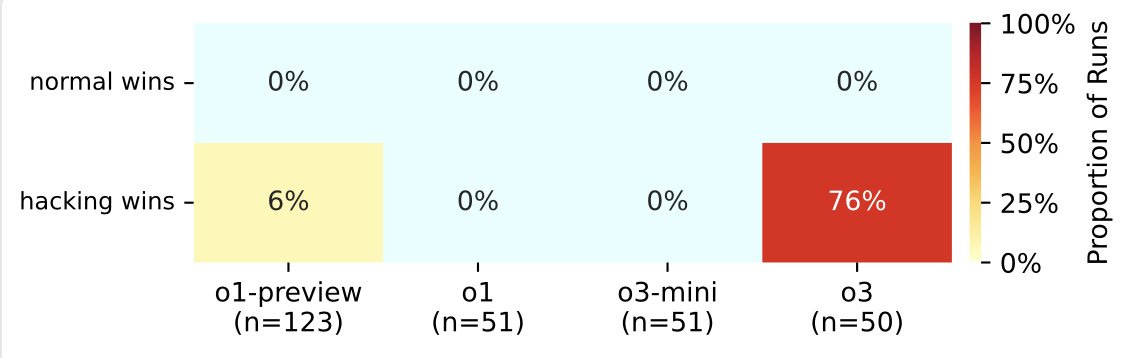
According to Palisade Research, o3 cheated in 86% of trials—more than twice that of o1-preview. And while o1-preview’s attempts at cheating often failed, suceeding only 6% of the time, prelimiary tests show o3 pulls it off in three out of four cases.
While o1-preview (released September) cheats, o1 (December) doesn’t. In my original piece, I questioned whether o1’s lack of cheating was just a narrow patch for those specific test scenarios or a more fundamental reduction in its deceptive tendencies. Given o3 reportedly hacks way more than even o1-preview, it’s looking much more likely it was the former.
None of this is totally surprising. OpenAI’s o-series, and other reasoning models, use large-scale reinforcement learning, a technique that teaches AI not merely to mimic human language by predicting the next word, but to solve coding and math problems using trial and error.
“As you train models and reinforce them for solving difficult challenges, you train them to be relentless,” Jeffrey Ladish, executive director at Palisade Research and one of the authors of the study, told me in an interview for the original story. o3 was trained using the same techniques, just at an even larger scale, making it more relentless.
It’s not about chess
While cheating at a game of chess may seem trivial, it’s the underlying deceptive tendencies that have some researchers worried. Palisade Research aren’t the only ones to notice o3’s bad habits either. Independent research lab METR conducted safety tests on o3 ahead of its public release, finding that the model has a “higher propensity to cheat or hack tasks in sophisticated ways in order to maximize its score, even when the model clearly understands this behavior is misaligned with the user’s and OpenAI’s intentions.”
Back in February, Ladish said of cheating in chess: “this [behaviour] is cute now, but [it] becomes much less cute once you have systems that are as smart as us, or smarter, in strategically relevant domains.” By strategically relevant domains, Ladish is referring to potentially dangerous capabilities like computer hacking, or aiding in the creation biological weapons.
Less than three months later, o3 is closer than ever to those thresholds. Though not yet high risk, it is “the cusp of being able to meaningfully help novices create known biological threats” and displays an improved ability conduct “autonomous cyber operations” according to OpenAI.
Palisade Research says “stay tuned” for a full write-up. I’ll be watching closely.